linux性能分析-开篇
性能问题的本质,就是系统资源已经达到瓶颈,但请求的处理却还不够快,无法支撑更多的请求。
性能分析,其实就是找出应用或系统的瓶颈,并设法去避免或者缓解他们, 从而更高效地利用系统资源处理更多的请求。这包含以下步骤:
- 选择指标评估应用程序和系统的性能;
- 为应用程序和系统设置性能目标;
- 进行性能基准测试;
- 性能分析定位瓶颈;
- 优化系统和应用程序;
- 性能监控告警。
CPU篇
平均负载
$ uptime
00:32:56 up 7 days, 16:48, 1 user, load average: 0.38, 0.11, 0.03
00:32:56 // 当前时间
up 7 days, 16:48, // 启动时间
1 user, // 登录用户数量
load average: 0.38, 0.11, 0.03 // 近 1、 5、 15 分钟的平均负载System load averages is the average number of processes that are either in a runnable or uninterruptable state. A process in a runnable state is either using the CPU or waiting to use the CPU. A process in uninterruptable state is waiting for some I/O access, eg waiting for disk.
不可中断状态的进程是正处于内核态关键流程中的进程,并且这些流程是不可打断的,比如最常见的是等待硬件设备的 I/O 响应,也就是我们在 ps 命令中看到的 D 状态(Uninterruptible Sleep, 也称为 Disk Sleep)的进程。
比如,当一个进程向磁盘读写数据时,为了保证数据的一致性,在得到磁盘回复前,它是不能被其他进程或者中断打断的,这个时候的进程就处于不可中断的状态。如果此时的进程被打断了,就容易出现磁盘数据与进程数据不一致的问题。
所以,不可中断状态实际上是系统对进程和硬件设备的一种保护机制。
平均负载表示的意义跟 CPU 的数量有直接的关系。如果平均负载为 2, 对于 2 核 CPU 来说刚好每个CPU 充分利用,对于 4 核 CPU 来说有 50% 的空闲,对于 1 核 CPU 来说有一半进程竞争不到 CPU。
可以通过 top 或者 /proc/cpuinfo 来查看系统有多少个核
$ grep "processor" /proc/cpuinfo | wc -l
4
// top 显示系统状态后,按 1 可以显示每个 cpu 的信息
$ top
top - 00:53:53 up 7 days, 17:09, 1 user, load average: 0.00, 0.02, 0.00
Tasks: 152 total, 1 running, 151 sleeping, 0 stopped, 0 zombie
%Cpu0 : 0.3 us, 1.3 sy, 0.0 ni, 98.0 id, 0.3 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu1 : 0.3 us, 0.3 sy, 0.0 ni, 98.7 id, 0.7 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu2 : 0.0 us, 0.7 sy, 0.0 ni, 99.0 id, 0.3 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu3 : 0.0 us, 0.3 sy, 0.0 ni, 99.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 3790.1 total, 611.9 free, 251.1 used, 2927.1 buff/cache
MiB Swap: 0.0 total, 0.0 free, 0.0 used. 3341.3 avail Mem平均负载与使用率
使用率是指 单位时间内占用 CPU 的统计,跟平均负载不一定能完全对应的上。
- 当任务是 CPU 密集型时,使用大量 CPU 会导致平均负载升高,此时二者是一致的。
- 当任务是 IO 密集型时,等待的 IO 也会导致平均负载升高,但 CPU 使用率不一定升高
- 大量等待 CPU 调度的任务,也会导致平均负载升高,此时 CPU 使用率也会升高
平均负载的案例分析
我们以三个示例分别来看这三种情况,并用 iostat、mpstat、pidstat 等工具,找出平均负载升高的根源。
机器配置:2 cpu,8 GB
安装软件:stress 和 sysstat
场景1 CPU 密集型
终端1
stress --cpu 1 --timeout 600终端2
watch -d uptime终端 3
mpstat -P ALL 5// mpstat
01:19:05 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
01:19:10 all 25.19 0.00 0.60 0.00 0.00 0.00 0.00 0.00 0.00 74.21
01:19:10 0 0.00 0.00 0.60 0.00 0.00 0.00 0.00 0.00 0.00 99.40
01:19:10 1 0.80 0.00 1.40 0.00 0.00 0.00 0.00 0.00 0.00 97.80
01:19:10 2 0.00 0.00 0.40 0.00 0.00 0.00 0.00 0.00 0.00 99.60
01:19:10 3 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
// uptime
Every 2.0s: uptime pi: Sat Oct 14 01:19:42 2023
01:19:42 up 7 days, 17:34, 4 users, load average: 1.03, 0.79, 0.41使用 pidstat 查看是那个进程导致cpu 使用率高
$ pidstat -u 5 1
Average: UID PID %usr %system %guest %wait %CPU CPU Command
Average: 0 14 0.00 0.20 0.00 0.00 0.20 - ksoftirqd/0
Average: 0 873 0.59 0.39 0.00 0.00 0.98 - rpimonitord
Average: 0 965385 0.00 0.20 0.00 0.00 0.20 - kworker/u8:1-events_unbound
Average: 0 968344 0.00 0.20 0.00 0.00 0.20 - kworker/3:2-events
Average: 1000 970054 0.20 0.00 0.00 0.00 0.20 - mpstat
Average: 1000 972273 99.41 0.00 0.00 0.20 99.41 - stress
Average: 1000 972295 0.59 1.18 0.00 0.00 1.77 - pidstatIO 密集型
终端1
stress -i 1 --timeout 600终端2
watch -d uptime终端 3
mpstat -P ALL 501:31:20 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
01:31:25 all 0.48 0.21 20.88 5.18 0.00 0.74 0.00 0.00 0.00 72.52
01:31:25 0 0.25 0.25 6.70 0.00 0.00 3.23 0.00 0.00 0.00 89.58
01:31:25 1 0.81 0.00 14.98 4.66 0.00 0.20 0.00 0.00 0.00 79.35
01:31:25 2 0.80 0.40 48.29 12.27 0.00 0.00 0.00 0.00 0.00 38.23
01:31:25 3 0.00 0.20 10.84 2.81 0.00 0.00 0.00 0.00 0.00 86.14查看哪个进程占用比较高
$ pidstat -u 5 1
Average: UID PID %usr %system %guest %wait %CPU CPU Command
Average: 0 14 0.00 0.20 0.00 0.20 0.20 - ksoftirqd/0
Average: 0 873 0.59 0.79 0.00 0.20 1.38 - rpimonitord
Average: 0 612965 0.00 1.77 0.00 0.00 1.77 - kworker/3:1H-kblockd
Average: 0 635939 0.00 4.13 0.00 0.20 4.13 - kworker/2:1H-kblockd
Average: 0 770334 0.00 8.64 0.00 0.00 8.64 - kworker/1:2H-kblockd
Average: 0 965385 0.00 0.20 0.00 0.00 0.20 - kworker/u8:1-events_power_efficient
Average: 1000 968472 0.00 0.20 0.00 0.00 0.20 - sshd
Average: 0 968963 0.00 0.39 0.00 0.00 0.39 - kworker/0:2H-kblockd
Average: 1000 970054 0.00 0.20 0.00 0.00 0.20 - mpstat
Average: 0 971494 0.00 0.20 0.00 0.00 0.20 - kworker/u8:0-events_unbound
Average: 1000 972509 0.59 60.12 0.00 15.32 60.71 - stress
Average: 0 972736 0.00 0.20 0.00 0.20 0.20 - kworker/1:0-events
Average: 1000 972786 0.39 1.18 0.00 0.00 1.57 - pidstat大量进程的场景
终端1
stress -c 16 --timeout 600终端2
watch -d uptime终端 3
mpstat -P ALL 5查看是那个进程导致的
$ pidstat -u 5 1
Average: UID PID %usr %system %guest %wait %CPU CPU Command
Average: 0 873 0.37 0.74 0.00 0.55 1.10 - rpimonitord
Average: 1000 968472 0.18 0.18 0.00 0.18 0.37 - sshd
Average: 1000 970054 0.00 0.18 0.00 0.18 0.18 - mpstat
Average: 0 972708 0.00 0.18 0.00 0.00 0.18 - kworker/2:2-events
Average: 1000 972897 24.63 0.00 0.00 73.35 24.63 - stress
Average: 1000 972898 24.45 0.00 0.00 73.71 24.45 - stress
Average: 1000 972899 24.45 0.00 0.00 73.90 24.45 - stress
Average: 1000 972900 24.45 0.00 0.00 73.71 24.45 - stress
Average: 1000 972901 24.08 0.00 0.00 73.90 24.08 - stress
Average: 1000 972902 24.45 0.00 0.00 73.53 24.45 - stress
Average: 1000 972903 24.45 0.00 0.00 73.53 24.45 - stress
Average: 1000 972904 24.45 0.00 0.00 73.71 24.45 - stress
Average: 1000 972905 24.08 0.00 0.00 74.08 24.08 - stress
Average: 1000 972906 23.90 0.00 0.00 74.45 23.90 - stress
Average: 1000 972907 24.08 0.00 0.00 74.08 24.08 - stress
Average: 1000 972908 24.26 0.00 0.00 73.71 24.26 - stress
Average: 1000 972909 24.08 0.00 0.00 73.90 24.08 - stress
Average: 1000 972910 23.90 0.00 0.00 74.26 23.90 - stress
Average: 1000 972911 24.08 0.00 0.00 74.45 24.08 - stress
Average: 1000 972912 24.08 0.00 0.00 74.08 24.08 - stress
Average: 1000 973008 0.18 1.29 0.00 4.60 1.47 - pidstat上下文切换
根据任务的不同,上下文切换分为进程上下文切换、线程上下文切换和中断上下文切换
系统调用导致的上下文切换属于特权模式切换。
进程的上下文切换只能发生在内核态。因此,进程的上下文不仅包括了虚拟内存、栈、全局变量等用户空间的资源,还包括了内核堆栈、寄存器等内核空间的状态。
注意:上下文切换后,虚拟内存发生变化导致 TLB 缓存也发生了变化,因此内存访问随之变慢。
中断上下文
中断上下文切换会打断进程的正常调度和执行。但是中断上下文切换并不涉及进程的用户态信息,它只包括内核态中断服务程序执行所必需的状态,包括 CPU 寄存器、内核堆栈、硬件中断参数等。
使用 vmstat 查看上下文
$ vmstat 5 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 151000 137400 3304624 0 0 6 16 7 6 1 1 98 0 0
1 0 0 150496 137400 3304652 0 0 0 0 135 143 1 0 99 0 0Cs: context switch 每秒钟上下文切换的次数
in(interrupt) 每秒中断的次数
r (running or runnable) 就绪队列的长度,也就是正在运行和等待 CPU 的进程数
b(blocked) 处于不可中断睡眠状态的进程数
vmstat只给出系统总体的上下文切换情况,使用 pidstat -w 可以查看每个进程上下文切换的情况
$ pidstat -w 5
Average: UID PID cswch/s nvcswch/s Command
Average: 0 2 0.20 0.00 kthreadd
Average: 0 14 3.47 0.00 ksoftirqd/0
Average: 0 15 5.56 0.00 rcu_preempt
Average: 0 16 0.30 0.00 migration/0
Average: 0 22 0.30 0.00 migration/1
Average: 0 23 0.50 0.00 ksoftirqd/1
Average: 0 28 0.30 0.00 migration/2
Average: 0 29 0.50 0.00 ksoftirqd/2
Average: 0 34 0.30 0.00 migration/3
Average: 0 35 0.20 0.00 ksoftirqd/3
Average: 0 48 1.98 0.00 kcompactd0
Average: 0 121 0.40 0.00 vchiq-slot/0
Average: 0 325 0.30 0.20 jbd2/mmcblk0p2-
Average: 0 436 0.99 0.00 multipathd
Average: 100 681 0.10 0.00 systemd-network
Average: 113 694 4.46 0.00 avahi-daemon
Average: 0 700 0.10 0.00 irqbalance
Average: 0 715 0.10 0.00 wpa_supplicant
Average: 0 873 1.39 0.69 rpimonitord
Average: 0 770334 0.30 0.00 kworker/1:2H-kblockd
Average: 0 968963 3.47 0.00 kworker/0:2H-mmc_complete
Average: 0 969676 0.10 0.00 packagekitd
Average: 1000 1276259 0.60 0.00 PM2 v5.3.0: God
Average: 1000 1276296 0.79 0.00 frpc这个结果中有两列是我们的重点关注对象。一个是 cswch,表示每秒自愿上下文切换(voluntary context switches)的次数,另一个则是 nvcswch, 表示每秒非自愿上下文切换 (non voluntary context switches) 的次数。
自愿上下文切换
是指进程无法获取所需自愿,导致的上下文切换。
- 比如说 I/O、内存等系统资源不足,就会发生自愿上下文切换。
非自愿上下文切换
是指进程由于时间片已到等原因,被系统强制调度,进而发生的上下文切换。
- 比如说,大量进程都在争抢CPU时,就容易发生非自愿上下文切换。
案例分析
工具:
- 预先安装 sysbench 和 sysstat 包
开启三个终端,分别运行以下命令
运行 sysbench
$ sysbench --threads=10 --max-time=300 threads run运行 vmstat
$ vmstat 1 r b swpd free buff cache si so bi bo in cs us sy id wa st 6 0 0 181132 134256 3249228 0 0 6 16 7 6 1 1 98 0 0 8 0 0 181132 134256 3249252 0 0 0 0 12932 93741 10 85 4 0 0 8 0 0 181132 134256 3249252 0 0 0 0 12298 85874 10 83 6 0 0
cs 从 6 上升到 一万多
运行 pidstat
$ pidstat -w -u 1 00:53:01 UID PID %usr %system %guest %wait %CPU CPU Command 00:53:02 0 1306510 0.00 1.00 0.00 0.00 1.00 2 kworker/u8:1-events_unbound 00:53:02 0 1309133 0.00 1.00 0.00 0.00 1.00 1 kworker/u8:3-events_unbound 00:53:02 1000 1310792 0.00 1.00 0.00 0.00 1.00 2 sshd 00:53:02 1000 1310895 0.00 1.00 0.00 2.00 1.00 1 sudo 00:53:02 0 1311165 31.00 316.00 0.00 0.00 347.00 0 sysbench 00:53:02 0 1311187 1.00 10.00 0.00 12.00 11.00 2 pidstat 00:53:01 UID PID cswch/s nvcswch/s Command 00:53:02 0 14 2.00 0.00 ksoftirqd/0 00:53:02 0 15 33.00 0.00 rcu_preempt 00:53:02 0 29 3.00 0.00 ksoftirqd/2 00:53:02 0 48 2.00 0.00 kcompactd0 00:53:02 0 325 3.00 2.00 jbd2/mmcblk0p2- 00:53:02 0 436 1.00 0.00 multipathd 00:53:02 0 968963 4.00 0.00 kworker/0:2H-mmc_complete 00:53:02 0 1306510 179.00 0.00 kworker/u8:1-events_unbound 00:53:02 0 1307264 14.00 0.00 kworker/3:2-events 00:53:02 0 1309133 292.00 0.00 kworker/u8:3-events_unbound 00:53:02 1000 1309283 1.00 0.00 sshd 00:53:02 0 1309585 25.00 0.00 kworker/0:2-events 00:53:02 0 1310710 21.00 0.00 kworker/1:1-events 00:53:02 1000 1310792 27.00 74.00 sshd 00:53:02 1000 1310876 1.00 1.00 sudo 00:53:02 1000 1310895 23.00 72.00 sudo 00:53:02 0 1310960 46.00 0.00 kworker/2:0-mm_percpu_wq 00:53:02 0 1311176 1.00 2.00 vmstat 00:53:02 0 1311187 1.00 585.00 pidstatSysbench cpu 使用率占到了 347 了
Ssh, pidstat 等非自愿切换较高
需要开启线程查看 pidstat 默认显示进程的指标数据,加上 -t 参数后,才会输出线程的指标
$ pidstat -wt 1
Average: UID TGID TID cswch/s nvcswch/s Command
Average: 0 1311460 - 0.12 0.29 sysbench
Average: 0 - 1311460 0.12 0.29 |__sysbench
Average: 0 - 1311461 1138.18 3511.70 |__sysbench
Average: 0 - 1311462 1121.66 3220.22 |__sysbench
Average: 0 - 1311463 1155.81 3361.57 |__sysbench
Average: 0 - 1311464 1221.29 3102.76 |__sysbench
Average: 0 - 1311465 998.19 3594.77 |__sysbench
Average: 0 - 1311466 1430.27 3108.32 |__sysbench
Average: 0 - 1311467 1183.28 3294.48 |__sysbench
Average: 0 - 1311468 1343.00 3063.10 |__sysbench
Average: 0 - 1311469 1258.53 3070.92 |__sysbench
Average: 0 - 1311470 1152.47 3281.14 |__sysbench
从上面结果可以看到,sysbench 进程的上下文切换次数看起来不多,但是他的子线程的上下文切换次数却有很多。
在上面观察指标时,发现中断次数也上升到 1 万多。
从 /proc/interrupts 中读取中断信息。
$ watch -d cat /proc/interrupts
...
IPI0: 1407944 1979950 1875295 1869838 Rescheduling interrupts
...变化速度最快的是重调度中断(RES),这个中断类型表示,唤醒空闲状态的 CPU 来调度新的任务运行。这是多处理系统中,调度器来分散任务到不同 CPU 的机制,通常也被称为处理器中断。
- Rescheduling Interrupts:
- 作用: 当一个 CPU 核心决定另一个 CPU 核心上的线程应该被重新调度时,它会发送一个重新调度中断。这通常发生在当前运行的线程被迁移到另一个 CPU 核心,或者当一个高优先级的线程准备在另一个 CPU 核心上运行时。
- 问题: 如果重新调度中断的数量非常高,这可能意味着系统中有大量的线程迁移。频繁的线程迁移可能会导致 CPU 缓存失效,从而降低性能。这可能是由于不恰当的线程亲和性设置、不恰当的调度策略或系统负载过高导致的。
- Function Call Interrupts:
- 作用: 这种中断用于在一个 CPU 核心上执行另一个 CPU 核心请求的函数。例如,当一个核心需要另一个核心来刷新其缓存时,它会发送一个函数调用中断。
- 问题: 高数量的函数调用中断可能意味着核心之间有大量的通信。这可能是由于多核心同步操作、锁争用或其他多核心交互导致的。频繁的函数调用中断可能会降低多核心性能,因为核心之间的通信通常比单核心操作要慢。
次数过多的问题:
- 性能下降: 如上所述,过多的 IPI 中断可能会导致性能下降,因为它们可能导致频繁的 CPU 缓存失效和核心之间的通信。
- 故障诊断: 如果你正在调试性能问题或系统行为,高数量的 IPI 中断可能会为你提供一些线索。例如,过多的重新调度中断可能意味着你需要查看线程的调度和亲和性设置。
小结
系统的上下文切换次数比较稳定,那么从数百到一万以内,都应该算是正常的。但是当上下文切换次数超过一万,或者切换次数出现数量级的增长时,就很可能已经出现了性能问题。
- 自愿上下文切换变多了,说明进程都在等待资源,有可能发生了 I/O 等其他问题
- 非自愿上下文切换变多了,说明进程都在被强制调度,也就是都在争抢 CPU,说明 CPU 的确成了瓶颈
- 中断次数变多了,说明 CPU 被中断处理程序占用,还需要通过查看 /proc/interrupts 文件具体的中断类型
基础篇:CPU 的使用率
/proc/stat 中系统 CPU 数据的含义
hahastrong@pi:/boot$ cat /proc/stat | grep ^cpu cpu 3634530 462833 4124233 428695707 700673 0 60100 0 0 0 cpu0 718245 111944 914312 107539593 128941 0 12788 0 0 0 cpu1 1032123 133393 1188697 106791708 219082 0 31781 0 0 0 cpu2 839941 104589 931099 107339296 193541 0 7679 0 0 0 cpu3 1044220 112906 1090124 107025107 159108 0 7851 0 0 0从左至右,一列列讲解
- user - us: 代表用户态 CPU 时间。不包括下面的 nice 时间,但包括了 guest 时间
- nice - ni: 代表低优先级用户态 CPU 时间,也就是进程的 nice 值被调整为 1-19 之间时的 CPU 时间。nice 的可取值范围是 -20 到 19,数值越大,优先级反而越低
- system - sys: 代表内核态 CPU 时间
- idel - id: 代表空闲时间。注意,它不包括等待 I/O 的时间
- iowait - wa: 代表等待 I/O 的 CPU 时间
- irq - hi: 代表处理硬中断的 CPU 时间
- softirq - si: 代表处理软中断的 CPU 时间
- stral - st: 代表当系统运行在虚拟机中的时候,被其他虚拟机占用的 CPU 时间
- guest - guest: 代表通过虚拟化运行其他操作系统的时间,也就是运行虚拟机的 CPU 时间
- guest_nice - gnice: 代表以低优先级运行虚拟机的时间
各个进程的 CPU 使用信息在 /proc/[pid]/stat
Top: 展示系统级别的 CPU 使用率,按 1 可以切换平均和各个 CPU 的详细数据
CPU 使用率过高怎么办?
如何找到哪个函数? 初期就使用 GDB 有点大材小用,可以先有使用 perf 。
perf 是 Linux 内置的性能分析工具。它以性能时间采样为基础,不仅可以分析系统的各种事件和内核性能,还可以用来分析指定应用程序的性能问题。
perf 的两种常见用法:
perf top -g
类似于 top, 它能够实时显示占用 CPU 时钟最多的函数或者指令,因此可以用来查找热点函数
Samples: 10K of event 'cycles', 4000 Hz, Event count (approx.): 744330318 lost: 0/0 d Overhead Shared Object Symbol 7.25% perf [.] __symbols__insert ◆ 5.77% perf [.] d_print_comp_inner ▒ 4.86% perf [.] rust_demangle_callback ▒ 3.31% perf [.] rb_next ▒ 2.34% [unknown] [k] 0xffffd95a71bdaa5c ▒ 2.27% [unknown] [k] 0xffffd95a70edc574 ▒ 1.95% perf [.] d_count_templates_scopes ▒ 1.67% perf [.] d_print_comp ▒ 1.66% [unknown] [k] 0xffffd95a71be47f0 ▒ 1.64% [unknown] [k] 0xffffd95a70e2c4ec ▒ 1.55% perf [.] dso__load_sym_internal- 第一列 Overhead, 是该符号的性能事件在所有采样中的比例,用百分比来表示
- 第二列 Shared,是该函数或指令所在的动态共享对象( Dynamic Shared Object), 如内核、进程名、动态链接库名、内核模块名等
- 第三列 Object,是动态共享对象的类型。 比如 [.] 表示用户空间的可执行程序、或者动态链接库,[k] 表示内核空间
perf record -g 和 perf report
perf top 无法保存数据,用于离线或者后续的分析。
perf record 提供了保存数据的功能,保存后的数据,使用 perf report 解析展示
$ perf record // 按 Ctrl + C $ perf report
在使用中,为 perf record 和 perf top 加上 -g 参数,开启调用关系的采样,方便我们根据调用链来分析性能问题
案例分析:CPU 使用率高了,但找不到高的CPU应用
使用 top, pidstat 等工具都无法看到占用 CPU 较高的进程,并且 top 中 task 正在运行的数量多于已知的线程数(这个如果一个主机运行大量的程序,也比较难判断)。
对于这种情况需要查看是不是存在短时进程,也就是不断重启的进程。
使用 pstree 可以以 树 装来查看所有进程之间的关系
hahastrong@pi:~$ pstree
systemd─┬─PM2 v5.3.0: God─┬─frpc───6*[{frpc}]
│ └─10*[{PM2 v5.3.0: God}]
├─2*[agetty]
├─avahi-daemon───avahi-daemon
├─bluetoothd
├─containerd───10*[{containerd}]
├─cron
├─dbus-daemon
├─dockerd───11*[{dockerd}]
├─hciattach
├─irqbalance───{irqbalance}
├─multipathd───6*[{multipathd}]
├─networkd-dispat
├─packagekitd───2*[{packagekitd}]
├─polkitd───2*[{polkitd}]
├─rpimonitord───2*[rpimonitord]
├─rsyslogd───3*[{rsyslogd}]
├─snapd───10*[{snapd}]
├─sshd───sshd───sshd───bash───pstree
├─systemd───(sd-pam)
├─systemd-journal
├─systemd-logind
├─systemd-network
├─systemd-resolve
├─systemd-timesyn───{systemd-timesyn}
├─systemd-udevd
├─unattended-upgr───{unattended-upgr}
├─v2ray───8*[{v2ray}]
└─wpa_supplicantexecsnoop是一个专为短时进程设计的工具。他通过 ftrace 实时监控进程的 exec() 行为,并输出短时进程的基本信息,包括进程 PID、父进程 PID、命令行参数以及执行的结果
USAGE: execsnoop [-hrt] [-a argc] [-d secs] [name]
-d seconds # trace duration, and use buffers
-a argc # max args to show (default 8)
-r # include re-execs
-t # include time (seconds)
-h # this usage message
name # process name to match (REs allowed)
eg,
execsnoop # watch exec()s live (unbuffered)
execsnoop -d 1 # trace 1 sec (buffered)
execsnoop grep # trace process names containing grep
execsnoop 'udevd$' # process names ending in "udevd"小结
碰到常规问题无法解释的 CPU 使用率时,首先要想到有可能是短时应用导致的问题
- 第一,应用里直接调用了其他二进制程序,这些程序通常运行时间比较短,通过 top 等工具也不容易发现
- 第二,应用本身在不停地崩溃重启,而启动过程的资源初始化,很可能会占用相当多的 CPU
案例分析:系统中出现大量不可中断进程和僵尸进程
使用 top 来查看各个进程的状态
$ top
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
28961 root 20 0 43816 3148 4040 R 3.2 0.0 0:00.01 top
620 root 20 0 37280 33676 908 D 0.3 0.4 0:00.01 app
1 root 20 0 160072 9416 6752 S 0.0 0.1 0:37.64 systemd
1896 root 20 0 0 0 0 Z 0.0 0.0 0:00.00 devapp
2 root 20 0 0 0 0 S 0.0 0.0 0:00.10 kthreadd
4 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 kworker/0:0H
6 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 mm_percpu_wq
7 root 20 0 0 0 0 S 0.0 0.0 0:06.37 ksoftirqd/0- R 是 Running 或 Runnable 的缩写,表示进程在 CPU 的就绪队列中,正在运行或者正在等待运行
- D 是 Disk Sleep 的缩写,也就是不可中断状态睡眠(Uninterruptible Sleep),一般表示进程正在跟硬件交互,并且交互过程不允许被其他进程或中断打断
- Z 是 Zombie 的缩写,他表示僵尸进程,也就是进程实际上已经结束了,但是父进程还没有回收它的资源
- S 是 Interruptible Sleep 的缩写,也就是可中断状态睡眠,表示进程因为等待某个事件而被系统挂起。当进程等待的事件发生时,他会被唤醒并进入 R 状态
- I 是 Idle 的缩写,也就是空闲状态,用在不可中断睡眠的内核线程上。
正常情况下,不可中断在很短的时间内就会结束,但如果系统或硬件发生了故障,进程可能会在不可中断状态保持很久,甚至系统中出现大量不可中断进程。这时,需要注意下,系统是不是出现了 I/O 等性能问题
dstat 是一个新的性能工具,它吸收了 vmstat、iostat、ifstat 等几种工具的有点,可以同时观察系统的 CPU、磁盘 I/O、网络以及内存使用情况。
hahastrong@pi:~/code/linuxperformance$ dstat
You did not select any stats, using -cdngy by default.
--total-cpu-usage-- -dsk/total- -net/total- ---paging-- ---system--
usr sys idl wai stl| read writ| recv send| in out | int csw
1 1 98 0 0| 26k 106k| 0 0 | 0 0 | 160 194
0 1 99 0 0| 0 0 | 426B 790B| 0 0 | 190 162
0 0 100 0 0| 0 0 | 66B 342B| 0 0 | 61 70
0 0 100 0 0| 0 0 | 769B 673B| 0 0 | 122 143使用 ps 查看进程的状态
$ ps aux | grep /app
root 4009 0.0 0.0 4376 1008 pts/0 Ss+ 05:51 0:00 /app
root 4287 0.6 0.4 37280 33660 pts/0 D+ 05:54 0:00 /app
root 4288 0.6 0.4 37280 33668 pts/0 D+ 05:54 0:00 /app从这个界面,我们可以发现多个 app 进程已经启动,并且他们的状态分别是 Ss+ 和 D+. 其中,S 表示可中断睡眠状态,D 表示不可中断睡眠。 s 表示这个进程是一个会话的领导进程,而 + 表示前台进程。
- 进程组:表示一组相互关联的进程,比如每个子进程都是父进程所在组的成员
- 会话,是指共享一个控制终端的一个或多个进程组
strace 查看进程执行过程中涉及到的调用
$ strace -p pidstat 查看CPU 和 I/O
# 间隔1秒输出10组数据
$ dstat 1 10
You did not select any stats, using -cdngy by default.
--total-cpu-usage-- -dsk/total- -net/total- ---paging-- ---system--
usr sys idl wai stl| read writ| recv send| in out | int csw
0 0 96 4 0|1219k 408k| 0 0 | 0 0 | 42 885
0 0 2 98 0| 34M 0 | 198B 790B| 0 0 | 42 138
0 0 0 100 0| 34M 0 | 66B 342B| 0 0 | 42 135
0 0 84 16 0|5633k 0 | 66B 342B| 0 0 | 52 177
0 3 39 58 0| 22M 0 | 66B 342B| 0 0 | 43 144
0 0 0 100 0| 34M 0 | 200B 450B| 0 0 | 46 147
0 0 2 98 0| 34M 0 | 66B 342B| 0 0 | 45 134
0 0 0 100 0| 34M 0 | 66B 342B| 0 0 | 39 131
0 0 83 17 0|5633k 0 | 66B 342B| 0 0 | 46 168
0 3 39 59 0| 22M 0 | 66B 342B| 0 0 | 37 134观察 wai 和 dsk 的 read,可以发现每当 read 较多时,wai 的值也比较高。这就说明 iowait 的升高跟磁盘读请求有关,很可能就是磁盘读导致的。
这时候可以通过 ps 来观察哪些进程是 D 状态
# 观察一会儿按 Ctrl+C 结束
$ top
...
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
4340 root 20 0 44676 4048 3432 R 0.3 0.0 0:00.05 top
4345 root 20 0 37280 33624 860 D 0.3 0.0 0:00.01 app
4344 root 20 0 37280 33624 860 D 0.3 0.4 0:00.01 app
...
找到 D 状态的进程,继续使用 pidstat 来详细查看该进程的一些指标
# -d 展示 I/O 统计数据,-p 指定进程号,间隔 1 秒输出 3 组数据
$ pidstat -d -p <pid> 1 3
# 查看全部的进程
$ pidstat -d 1 20
06:48:46 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
06:48:47 0 4615 0.00 0.00 0.00 1 kworker/u4:1
06:48:47 0 6080 32768.00 0.00 0.00 170 app
06:48:47 0 6081 32768.00 0.00 0.00 184 app
06:48:47 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
06:48:48 0 6080 0.00 0.00 0.00 110 app从统计结果可以看出,app 进程存在大量读请求
接着使用 strace 来查看该进程进行了哪些系统调用
$ strace -p pid如何这个时候出现 operation not permitted,说明这个进程可能已经是非活跃的了。使用 ps 来进一步验证
$ ps aux | grep pid接下来,基础我们的大杀器,perf,使用该命令来查看占比较高的调用
# -g 表示查看调用链
$ perf record -g
$ perf report针对僵尸进程的处理办法
僵尸进程,需要找出他们的父进程,然后在父进程里解决
使用 pstree 来查看进程树
# -a 表示输出命令行选项
# p 表示 pid
# s 表示指定进程的父进程
$ pstree -aps <pid>
systemd,1 fixrtc splash
└─PM2 v5.3.0: God,1276259
└─frpc,1276296 -c frpc.ini
├─{frpc},1276298
├─{frpc},1276299
├─{frpc},1276301
├─{frpc},1276302
├─{frpc},1276305
└─{frpc},1276306小结
iowait 高并不一定代表 I/O 有性能瓶颈。当系统中只有 I/O 类型的进程在运行时,iowait 也会很高,但实际上,磁盘的读写远远没有达到性能瓶颈的程度。
Linux 软中断
进程的不可中断状态是系统的一种保护机制,可以保证硬件的交互过程不被意外打断。所以,短时间的不可中断状态是很正常
中断是系统用来响应硬件设备请求的一种机制,他会打断进程的正常调度和执行,然后调用内核中的中断处理程序来响应设备的请求。
中断是一种异步的事件处理机制,可以提高系统的并发处理能力。
Linux 将中断处理过程分成两个阶段,也就是上半部和下半部:
- 上半部分用来快速处理中断,他在中断禁止模式下运行,主要处理跟硬件紧密相关的或时间敏感的工作
- 下半部分用来延迟处理上半部分未完成的工作,通常以内核线程的方式运行(接收网络包)
软中断: 后续可以详细了解下~~
使用 cat /proc/softirqs 查看有哪些软中
hahastrong@pi:~$ cat /proc/softirqs
CPU0 CPU1 CPU2 CPU3
HI: 3 0 0 5
TIMER: 6409992 8784908 5368765 4744355
NET_TX: 63 681901 176 3097
NET_RX: 74468 14227409 75691 3775963
BLOCK: 3115022 1514533 1075785 1091438
IRQ_POLL: 0 0 0 0
TASKLET: 2098188 592 26 2376
SCHED: 10474125 12120599 9061687 8107934
HRTIMER: 55 29309 80 49
RCU: 7912606 8813982 7868592 8617938 # RCU 锁内核线程
hahastrong@pi:~$ ps -ef | grep '\['
root 2 0 0 Oct06 ? 00:00:05 [kthreadd]
root 3 2 0 Oct06 ? 00:00:00 [rcu_gp]
root 4 2 0 Oct06 ? 00:00:00 [rcu_par_gp]
root 5 2 0 Oct06 ? 00:00:00 [slub_flushwq]
root 6 2 0 Oct06 ? 00:00:00 [netns]
root 10 2 0 Oct06 ? 00:00:00 [mm_percpu_wq]
root 11 2 0 Oct06 ? 00:00:00 [rcu_tasks_kthre]
root 12 2 0 Oct06 ? 00:00:00 [rcu_tasks_rude_]
root 13 2 0 Oct06 ? 00:00:00 [rcu_tasks_trace]
root 14 2 0 Oct06 ? 00:01:43 [ksoftirqd/0]
root 15 2 0 Oct06 ? 00:07:28 [rcu_preempt]
root 16 2 0 Oct06 ? 00:00:11 [migration/0]
root 17 2 0 Oct06 ? 00:00:00 [idle_inject/0]
root 19 2 0 Oct06 ? 00:00:00 [cpuhp/0]
root 20 2 0 Oct06 ? 00:00:00 [cpuhp/1]
root 21 2 0 Oct06 ? 00:00:00 [idle_inject/1]
root 22 2 0 Oct06 ? 00:00:10 [migration/1]
root 23 2 0 Oct06 ? 00:01:51 [ksoftirqd/1]
root 26 2 0 Oct06 ? 00:00:00 [cpuhp/2]
root 27 2 0 Oct06 ? 00:00:00 [idle_inject/2]案例分析
准备工具
- 预先安装 docker. sysstat, sar, hping3, tcpdump
开干
在 1 号机器上起一个 nginx 服务
$ docker run -id --name=nginx -p 80:80 nginx在 2 号机器上查看性能
首先 curl
$ curl http://ip
接着运行 hping 命令,来模拟泛洪攻击
# -S 参数表示设置 TCP 协议的 SYN
# -p 表示目的端口为 80
# -i u100 表示每隔 100 微秒发送一个网络帧
$ hping3 -S -p 80 -i u100 <ip>使用 sar 查看网络数据包
hahastrong@hahastrong:~$ sar -n DEV 1
Linux 5.15.0-87-generic (hahastrong) 10/22/2023 _x86_64_ (2 CPU)
03:30:57 AM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
03:30:58 AM lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
03:30:58 AM ens33 10613.00 5304.00 621.86 310.89 0.00 0.00 0.00 0.51
03:30:58 AM docker0 5303.00 10608.00 227.86 559.41 0.00 0.00 0.00 0.00
03:30:58 AM vethddbe767 5303.00 10609.00 300.37 559.46 0.00 0.00 0.00 0.05CPU 性能问题排查套路
排查 CPU 涉及到的指标
CPU 的使用率
- 用户CPU、系统 CPU、等待 I/O CPU、软中断和硬中断
平均负载
- 理想情况下,平均负载等于逻辑 CPU 的个数,表示每个 CPU 都恰好被充分利用
进程上下文切换
- 无法获取资源而导致的资源上下文切换
- 被系统强制调度导致的非自愿上下文切换
CPU 缓存的命中率
- CPU 缓存的速度介于 CPU 和内存之间,缓存的是热点的内存数据。
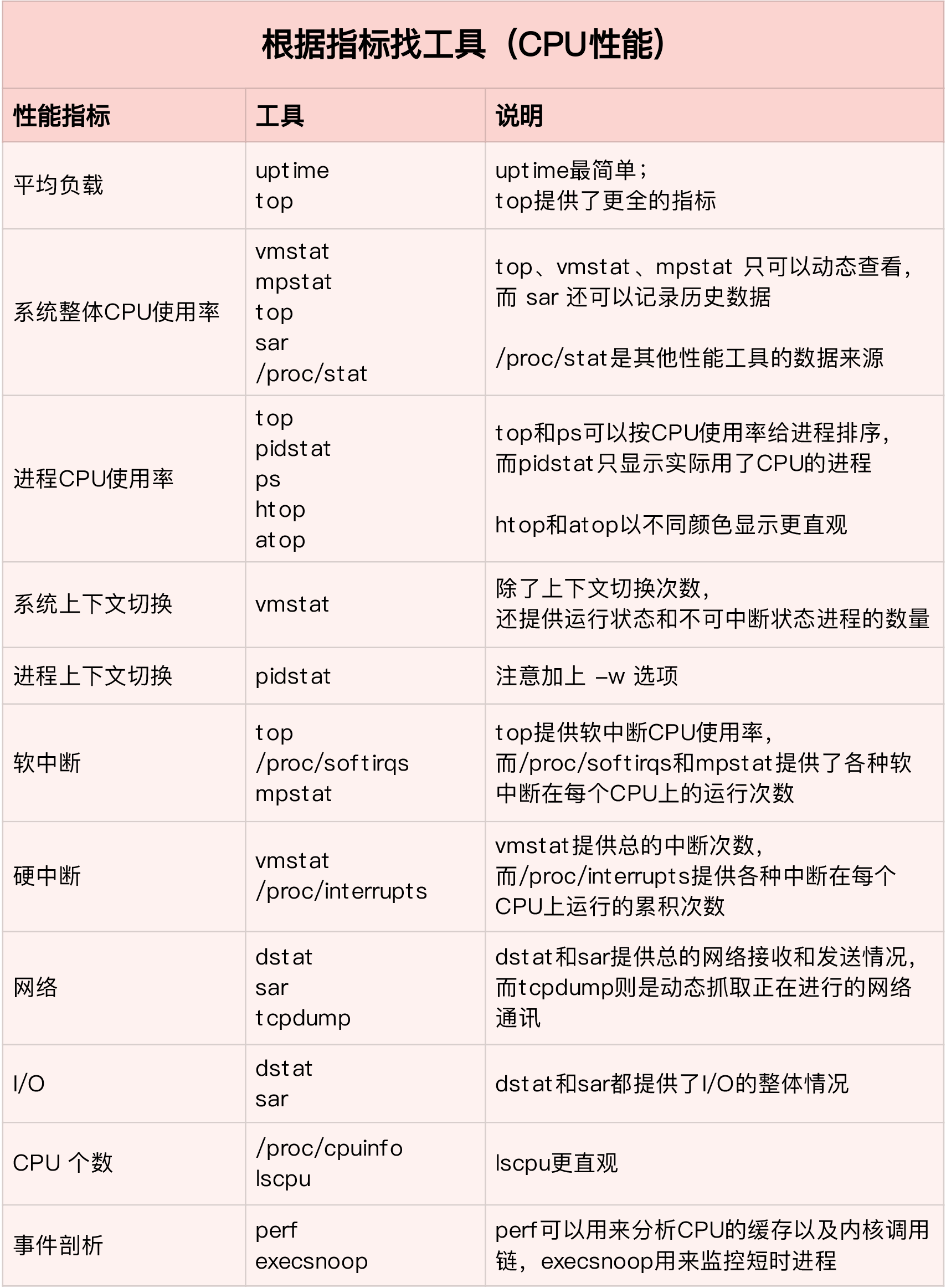
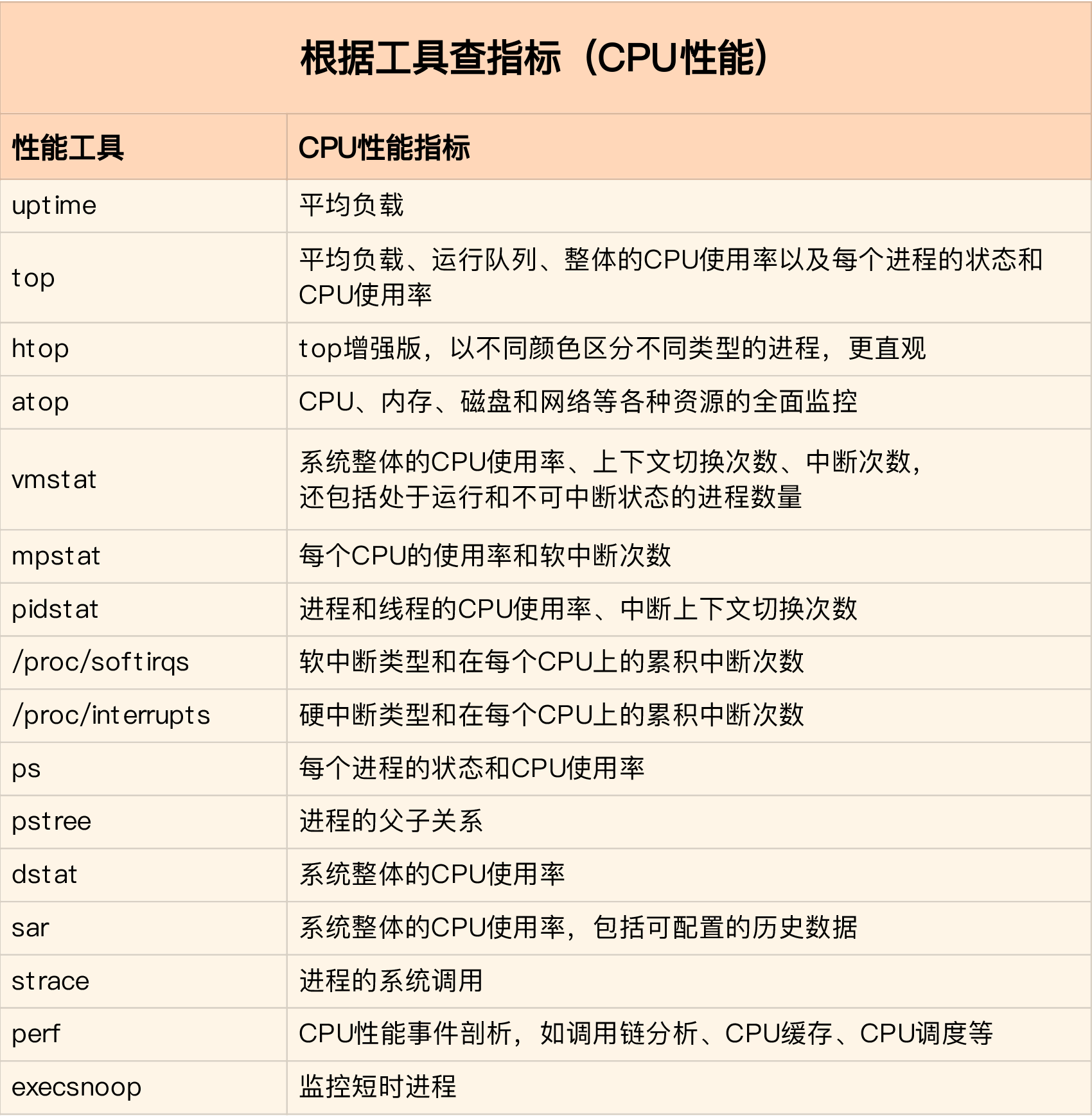
工具指标
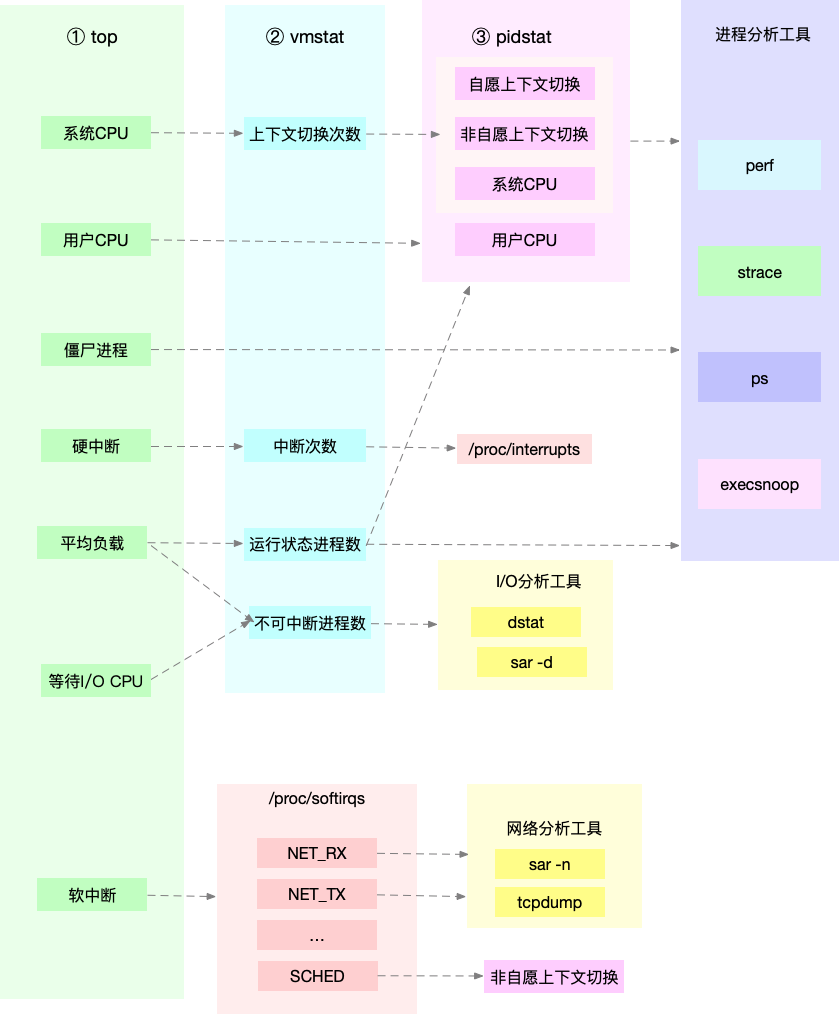
为了缩小排查范围,优先使用以下三个工具
- top, vmstat, pidstat
性能优化方法论
性能优化前需要考虑的问题
- 如何判断是否有效?优化后,性能可以提升多少?
- 性能问题通常不是独立的,如果有多个性能问题同时发生,我们应该先优化哪一个?
- 提升性能的方法并不是唯一的,当有多种方法可以选择时,我们需要选择哪一种呢?是不是总是选择性能提升程度最大的那个?
性能优化三步走
- 确定性能的量化指标
- 测试优化前的性能指标
- 测试优化后的性能指标
性能优化不要局限在单一维度的指标上,至少要从应用程序和系统资源这两个维度,分别选择不同的指标。以 Web 应用为例:
- 应用程序的维度,我们可以用吞吐量和请求延迟来评估应用程序的性能
- 系统资源的维度,我们可以用 CPU 使用率来评估系统的 CPU 使用情况
在性能测试领域,流传很广的一个说法是 “二八原则”, 也就是说 80% 的问题都是由 20% 的代码导致的。只要找出这 20% 的位置,我们就可以优化 80% 的性能。所以,并不是所有的性能问题都值得优化。
应用程序优化
- 编译器优化
- 算法优化
- 异步处理
- 多线程代替多进程
- 善用缓存
系统优化
- CPU 绑定:把进程绑定到一个或者多个 CPU 上,可以提高 CPU 缓存的命中率,减少跨 CPU 调度带来的上下文切换问题
- CPU 独占:跟 CPU 绑定类似,进一步将 CPU 分组,并通过 CPU 亲和性机制为其分配进程。这样,这些 CPU 就由指定的进程独占,换句话说,不允许其他进程再来使用这些 CPU
- 优先级调整
- 为进程设置资源限制:使用 Linux cgroups 来设置进程的 CPU 使用上限,可以防止由于某个应用自身的问题,而耗尽系统资源
- NUMA 优化:
- 中断负载均衡:无论是软中断还是硬中断,他们的中断处理程序都可能会耗费大量的 CPU。开启 irqbalance 服务或者配置 smp_affinity, 就可以把中断处理过程自动负载均衡到多个 CPU 上。
过早优化是万恶之源