linux内存性能分析
Linux 内核给每个进程都提供了一个独立的虚拟地址空间,并且这个地址空间是连续的。这样进程就可以很方便地访问内存,更确切地说是访问虚拟内存。
虚拟地址空间的内部又被分为内核空间和用户空间两部分。
虽然每个进程的地址空间都包含了内核空间,但这些内核空间,其实关联的都是相同的物理内存。
虚拟内存和物理内存,通过内存映射来管理。为了完成内存映射,内核为每个进程都维护了一张页表,记录虚拟地址与物理地址的映射关系。当进程访问的虚拟地址在页表中查不到时,系统会产生一个缺页异常,进入内核空间分配物理内存、更新进程页表,最后再返回用户空间,恢复进程的运行。
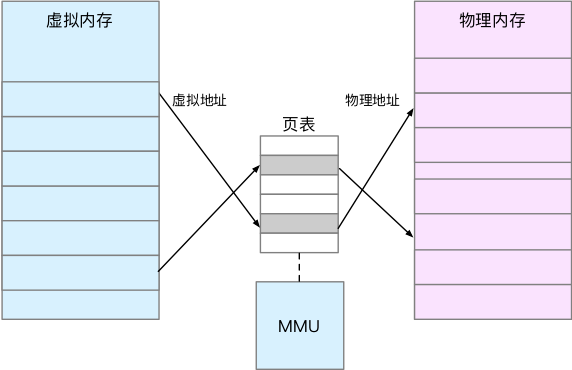
TLB (Translation Lookaside Buffer, 转译后备缓存器 ) 会影响 CPU 的内存访问性能,TLB 其实就是 MMU 中页表的高速缓存。
由于进程的虚拟地址空间时独立的,而 TLB 的访问速度又比 MMU 快得多,所以,通过减少进程的上下文切换,减少 TLB 的刷新次数,就可以提高 TLB 缓存的使用率,进而提高 CPU 的内存访问性能。
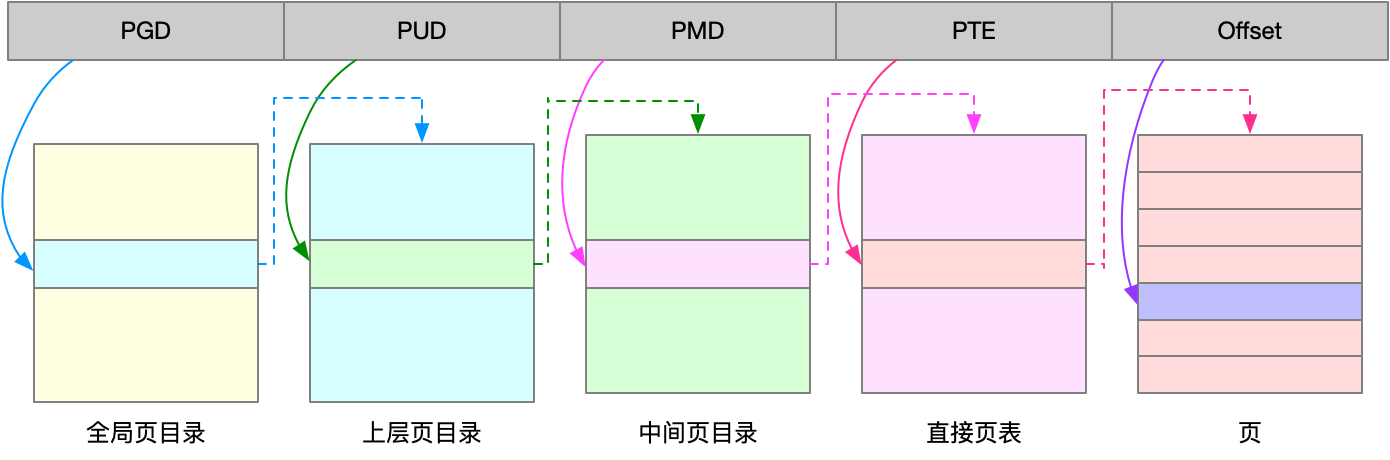
Linux 使用多级页表来管理内存。多级页表就是把俄内存分成区块来管理,将原来的映射关系改成区块索引和区块内的偏移。
虚拟空间内存分布
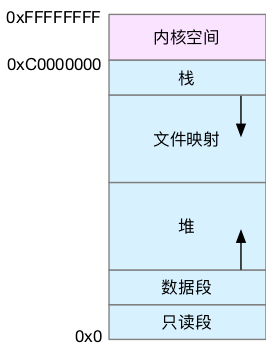
在这五个内存段中,堆和文件映射段的内存是动态分配的。比如说,使用 C 标准库的 malloc() 或 mmap() ,就可以分别在堆和文件映射段动态分配内存。
malloc 底层使用 brk 或者 mmap 来分配内存。这里后续需要详细了解下
内存紧张时,系统会通过一系列的机制来回收内存
- 回收缓存,比如使用 LRU 算法,回收最近使用最少的内存页面
- 回收不常访问的内存,把不常用的内存通过交换分区直接写到磁盘中
- 杀死进程,内存紧张时系统还会通过 OOM ,直接杀掉占用大量内存的进程
OOM 是通过 oom_score 分数来控制的,分数越高越容易被杀死,可以通过 /proc 文件系统,手动设置进程的 oom_adj, 从而调整进程的 oom_score。
Oom_adj 的范围是 [-17, 15], 数值越大,表示进程越容易被 OOM 杀死;数值越小,表示进程越不容易被 OOM 杀死,其中 -17 表示禁止 OOM
比如下面命令,可以把 sshd 进程设置为 -16
$ echo -16 > /proc/$(pidof sshd)/oom_adj如何查看内存使用情况
参考播客
https://blog.holbertonschool.com/hack-the-virtual-memory-malloc-the-heap-the-program-break/
free
$ free
total used free shared buff/cache available
Mem: 3881060 344980 744700 4088 2791380 3336264
Swap: 0 0 0available 是新进程可用内存大小,
查看进程占用内存
$ top
top - 00:58:26 up 18 days, 17:13, 1 user, load average: 0.00, 0.00, 0.00
Tasks: 165 total, 1 running, 164 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.1 us, 0.2 sy, 0.0 ni, 99.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 3790.1 total, 724.1 free, 339.9 used, 2726.1 buff/cache
MiB Swap: 0.0 total, 0.0 free, 0.0 used. 3255.1 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
2503043 hahastr+ 20 0 10376 3276 2684 R 1.0 0.1 0:00.17 top
2498801 root 20 0 0 0 0 I 0.3 0.0 0:00.89 kworker/3:2-eve+
1 root 20 0 169092 11088 6080 S 0.0 0.3 1:59.08 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:06.48 kthreadd
3 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 rcu_gp
4 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 rcu_par_gp
5 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 slub_内存中的 Buffer 和 Cache
buffer 和 cache 的介绍
buffers
Memory used by kernel buffers (Buffers in /proc/meminfo)
cache Memory used by the page cache and slabs (Cached and SReclaimable in
/proc/meminfo)buffers 是内核缓冲区用到的内存,对应的是 /proc/meminfo 中的 Buffers
cache 是内核页缓存和 slab 用到的内存,对应的是 /proc/meminfo 中的 cached 和 SReclaimable 之和
通过查看 proc 得到 这个文件系统的详细文档
Buffers %lu
Relatively temporary storage for raw disk blocks that shouldn't get tremendously large (20MB or so).
Cached %lu
In-memory cache for files read from the disk (the page cache). Doesn't include SwapCached.
...
SReclaimable %lu (since Linux 2.6.19)
Part of Slab, that might be reclaimed, such as caches.
SUnreclaim %lu (since Linux 2.6.19)
Part of Slab, that cannot be reclaimed on memory pressure.- Buffers 是对原始磁盘块的临时存储,也就是用来缓存磁盘的数据,通常只有 20 M。这样就可以将分散的写集中起来,统一优化磁盘的写入。
- Cached 是从磁盘读区文件的页缓存,用来缓存从文件读取的数据。这样下次就可直接从内存中快速获取,而不需要再次访问缓慢的磁盘了。
案例
在一个终端运行 vmstat , 观察 buffer 和 cache
$ vmstat 1
在另一个终端执行 dd 命令,通过读取随机设备,生成一个 500M 大小的文件
$ dd if=/dev/urandom of=/tmp/file bs=1M count=500
vmstat 的输出
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 7499460 1344 230484 0 0 0 0 29 145 0 0 100 0 0
1 0 0 7338088 1752 390512 0 0 488 0 39 558 0 47 53 0 0
1 0 0 7158872 1752 568800 0 0 0 4 30 376 1 50 49 0 0
1 0 0 6980308 1752 747860 0 0 0 0 24 360 0 50 50 0 0
0 0 0 6977448 1752 752072 0 0 0 0 29 138 0 0 100 0 0
0 0 0 6977440 1760 752080 0 0 0 152 42 212 0 1 99 1 0
...
0 1 0 6977216 1768 752104 0 0 4 122880 33 234 0 1 51 49 0
0 1 0 6977440 1768 752108 0 0 0 10240 38 196 0 0 50 50 0可以看出 cache 不断增长,buffer 基本保持不变
再进一步观察 I/O 的情况,我们可以看到
- 在 cache 刚开始增长时,块设备 I/O 很少,bi 只出现了一次,bo 则只有一次 4 kb/s. 而过一段时间后,才会出现大量的块设备写
- 当 dd 命令结束后,cache 不再增长,但块设备还会持续一段时间,并且多次 I/O 写的结果加起来,才是 dd 要写的 500M 数据
向块设备写入
$ echo 3 > /proc/sys/vm/drop_caches
$ dd if=/dev/urandom of=/dev/sdb1 bs=1M count=2048
观察 vmstat 的输出
$ vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 7584780 153592 97436 0 0 684 0 31 423 1 48 50 2 0
1 0 0 7418580 315384 101668 0 0 0 0 32 144 0 50 50 0 0
1 0 0 7253664 475844 106208 0 0 0 0 20 137 0 50 50 0 0
1 0 0 7093352 631800 110520 0 0 0 0 23 223 0 50 50 0 0
1 1 0 6930056 790520 114980 0 0 0 12804 23 168 0 50 42 9 0
1 0 0 6757204 949240 119396 0 0 0 183804 24 191 0 53 26 21 0
1 1 0 6591516 1107960 123840 0 0 0 77316 22 232 0 52 16 33 0从上面可以看出,虽然都是写数据,写磁盘跟写文件的现象还是不同的。写磁盘时,Buffer 和 Cache 都在增长,但 buff 增长的块得多
这说明写磁盘用到了大量的 Buffer。
总结
- Buffer 既可以用作 将要写入磁盘数据的缓存,也可以用作 从磁盘读区数据的缓存
- Cache 既可以用作 从文件读取数据的页缓存,也可以用作 写文件的页缓存
如何利用缓存个优化程序的运行效率
缓存命中率
缓存命中率,是指通过缓存获取数据的请求次数,占所有数据请求次数的百分比。
命中率越高,表示使用缓存带来的收益越高,应用程序的性能也就越好
工具
- cachestat 提供了整个操作系统缓存的读写命中情况
- cachetop 提供了每个进程的缓存命中情况
- pcstat 指定文件的缓存大小: go install github.com/tobert/pcstat@latest
需要安装 bcc 工具
https://github.com/iovisor/bcc/blob/master/INSTALL.md#ubuntu---source
export PATH=$PATH:/usr/share/bcc/tools
案例
测试文件读取
# 生成一个临时文件
$ dd if=/dev/sda1 of=file bs=1M count=512
# 清理缓存
$ echo 3 > /proc/sys/vm/drop_caches查看 file 文件的缓存
root@hahastrong:/home/hahastrong# pcstat file
+-------+----------------+------------+-----------+---------+
| Name | Size (bytes) | Pages | Cached | Percent |
|-------+----------------+------------+-----------+---------|
| file | 536870912 | 131072 | 0 | 0.000 |
+-------+----------------+------------+-----------+---------+在另一个终端中 运行 cachetop
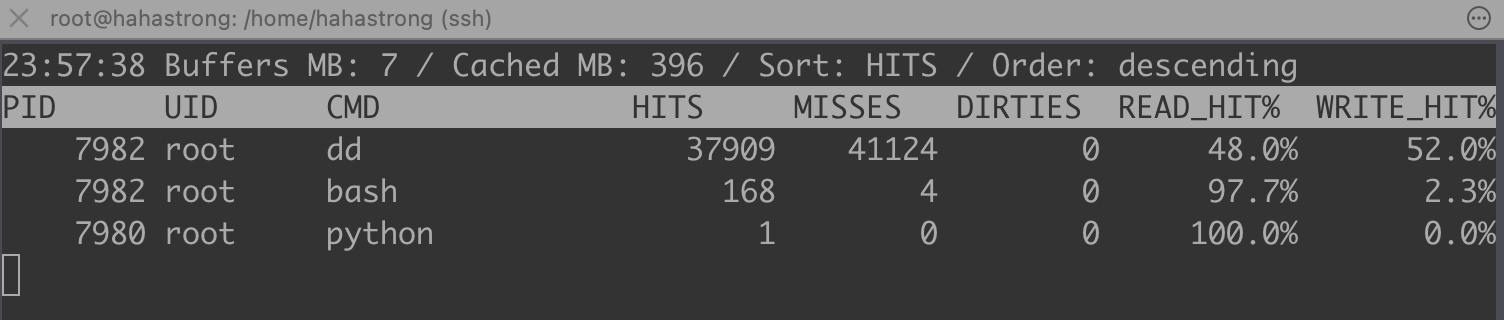
# 每隔五秒刷新一次数据
$ cachetop 1
在第一个终端中,运行 dd 命令测试文件的读取速度
$ dd if=file of=/dev/numm bs=1M
root@hahastrong:/home/hahastrong# dd if=file of=/dev/null bs=1M
512+0 records in
512+0 records out
536870912 bytes (537 MB, 512 MiB) copied, 0.374987 s, 1.4 GB/s
# 第二次
root@hahastrong:/home/hahastrong# dd if=file of=/dev/null bs=1M
512+0 records in
512+0 records out
536870912 bytes (537 MB, 512 MiB) copied, 0.161763 s, 3.3 GB/s从 cachetop 的结果来看,读请求的缓存命中率只有 50 %
再次执行相同的 dd 命令时,磁盘的读性能提高 3 倍。
看来 file 文件被系统缓存了,我们使用。pcstat 来验证下
root@hahastrong:/home/hahastrong# pcstat file
+-------+----------------+------------+-----------+---------+
| Name | Size (bytes) | Pages | Cached | Percent |
|-------+----------------+------------+-----------+---------|
| file | 536870912 | 131072 | 131072 | 100.000 |
+-------+----------------+------------+-----------+---------+从上述数据中,可以发现 file 文件已经被全部缓存了,命中率是 100%
案例2 不可中断进程的读
如何程序直接读取文件,绕过系统缓存,也会导致看起来命中率 100%,实际上很少文件走系统缓存。
此时,借助 strace 查看程序以什么方式打开文件,如果参数中有 O_DIRECT 则需要去掉
$ strace -p $(pgrep app)
...
openat(AT_FDCWD, "/dev/sdb1", O_RDONLY|O_DIRECT)
...直接IO是跳过Buffer,裸IO是跳过文件系统(还是有buffer的)
内存泄漏了,如何快速定位和处理
进程可以自主申请内存,以及可能存在内存泄漏的区域 – 堆 和 内存映射段
使用 bcc 的 memleak 可以查看内存泄漏问题
root@hahastrong:/home/hahastrong# memleak -a -p $(pidof app)
Attaching to pid 8190, Ctrl+C to quit.
[00:36:50] Top 10 stacks with outstanding allocations:
addr = 7f6858268260 size = 8192
addr = 7f6858262230 size = 8192
addr = 7f6858266250 size = 8192
addr = 7f6858264240 size = 8192
32768 bytes in 4 allocations from stack
0x000056485fa00879 fibonacci+0x1f [app] ## 内存泄漏的函数
0x000056485fa008ea child+0x4f [app]
0x00007f685d2dc6db start_thread+0xdb [libpthread-2.27.so]
[00:36:55] Top 10 stacks with outstanding allocations:
addr = 7f6858268260 size = 8192
addr = 7f685826a270 size = 8192
addr = 7f6858262230 size = 8192
addr = 7f68582702a0 size = 8192
addr = 7f6858266250 size = 8192
addr = 7f6858264240 size = 8192
addr = 7f68582722b0 size = 8192
addr = 7f685826c280 size = 8192
addr = 7f685826e290 size = 8192
73728 bytes in 9 allocations from stack
0x000056485fa00879 fibonacci+0x1f [app]
0x000056485fa008ea child+0x4f [app]
0x00007f685d2dc6db start_thread+0xdb [libpthread-2.27.so]为什么系统的 Swap 变高了
内存回收,也就是系统释放掉可以回收的内存,比如前面提到的缓存和缓冲区,就属于可回收内存。他们在内存管理中,通常被叫做文件页(Filebacked Page)
大部分文件页,都可以直接回收,以后有需要时,再从磁盘重新读取就可以了。而哪些被应用程序修改过,并且暂时还没写入磁盘的数据,就得先写入磁盘,然后才能进行内存释放。(内存页中会有个dirty 标识)
对于应用程序申请的堆内存(匿名页),系统没法直接释放,需要使用 swap 机制,将这些不常访问的内存先写到磁盘中,然后释放这些内存,给其他更需要的进程使用。
Swap 原理
swap 将一块磁盘空间或者一个本地文件当成内存来使用。它包括换入和换出两个过程
- 换出,就是把进程暂时不用的内存数据存储到磁盘中,并释放这些数据占用的内存
- 换入,则是在进程再次访问这些内存时,把他们从磁盘中读到内存中来。
常见的笔记本电脑的休眠和快速开机的功能,都是基于 swap 的。
内存回收的场景
- 直接内存回收:有新的大块内存分配请求,但是剩余内存不足。这个时候系统就需要回收一部分内存(比如前面提到的缓存),进而尽可能地满足新内存请求
- 定期内存回收:系统中有一个专门的内核线程来定期回收内存(kswapd0)。为了衡量内存的使用情况,kswapd0 定义了三个内存阈值(watermark,也称为水位),分别是
- 页最小阈值(pages_min)
- 页最低阈值(pages_low)
- 页最高阈值(pages_high)
- 剩余内存使用 pages_free 表示

定期内存回收策略
- 剩余内存小于 页最小阈值:说明进程可用内存都耗尽了,只有内核才可以分配内存
- 剩余内存落在页最小阈值和页低阈值中间,说明内存压力比较大剩余内存不多了。这时 kswapd0 会执行内存回收, 直至剩余内存大于高阈值为止。
- 剩余内存落在页低阈值和页高阈值中间,说明内存有一定压力,但还可以满足新内存请求
- 剩余内存大于页高阈值,说明剩余内存比较多,没有内存压力
页低阈值
/proc/sys/vm/min_free_kbytes
45056
NUMA 和 swap
有时候,可用内存还很多,但还是发生了 swap,可能是 numa,导致每个 node 拥有自己的本地内存空间
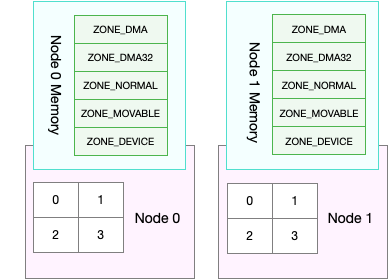
查看内存使用信息
$ cat /proc/zoneinfo
Node 0, zone DMA
per-node stats
nr_inactive_anon 43304
nr_active_anon 982
nr_inactive_file 375495
nr_active_file 366544
nr_unevictable 8460
nr_slab_reclaimable 80804
nr_slab_unreclaimable 17511
nr_isolated_anon 0
nr_isolated_file 0
workingset_nodes 7693
workingset_refault_anon 0
workingset_refault_file 4745613
workingset_activate_anon 0
workingset_activate_file 1801658
workingset_restore_anon 0
workingset_restore_file 708146
workingset_nodereclaim 118059
nr_anon_pages 50821
nr_mapped 35310
nr_file_pages 743964
nr_dirty 7
nr_writeback 0
nr_writeback_temp 0
nr_shmem 970
nr_shmem_hugepages 0
nr_shmem_pmdmapped 0
nr_file_hugepages 0
nr_file_pmdmapped 0
nr_anon_transparent_hugepages 0
nr_vmscan_write 0
nr_vmscan_immediate_reclaim 19382
nr_dirtied 28710062
nr_written 27975958
nr_kernel_misc_reclaimable 0
nr_foll_pin_acquired 630
nr_foll_pin_released 630
nr_kernel_stack 4336
nr_page_table_pages 1162
nr_swapcached 0
pages free 22000
min 2453
low 3066
high 3679
spanned 262144
present 242688
managed 220517
cma 16384
protection: (0, 2928, 2928, 2928)
nr_free_pages 22000
nr_zone_inactive_anon 636 // 匿名页
nr_zone_active_anon 10
nr_zone_inactive_file 95512 // 文件页
nr_zone_active_file 71928
nr_zone_unevictable 0
nr_zone_write_pending 0
nr_mlock 0
nr_bounce 0
nr_zspages 0
nr_free_cma 897
pagesets
cpu: 0
count: 182
high: 766
batch: 63
vm stats threshold: 24
cpu: 1
count: 311
high: 766
batch: 63
vm stats threshold: 24
cpu: 2
count: 685
high: 766
batch: 63
vm stats threshold: 24
cpu: 3
count: 676
high: 766
batch: 63
vm stats threshold: 24
node_unreclaimable: 0
start_pfn: 0查看进程换出的虚拟内存
$ cat /proc/pid/staus | grep VmSwap
// 用于查看进程换出的 虚拟内存大小
VmPeak: 119476 kB
VmSize: 119476 kB
VmLck: 0 kB
VmPin: 752 kB
VmHWM: 21412 kB
VmRSS: 13276 kB
RssAnon: 10464 kB
RssFile: 2812 kB
RssShmem: 0 kB
VmData: 45360 kB
VmStk: 132 kB
VmExe: 3100 kB
VmLib: 18560 kB
VmPTE: 256 kB
VmSwap: 0 kB查看最大虚拟内存排行
$ for line in /proc/*/status ; do awk '/VmSwap|Name|^Pid/{printf $2 " " $3}END {print ""}' $line; done | sort -k 3 -n -r | head
writeback 21
watchdogd 78
vfio-irqfd-clea 91
v2ray 137053 0 kB
tpm_dev_wq 73
systemd-udevd 246 0 kB
systemd-resolve 416 0 kB
systemd-network 404 0 kB
systemd-logind 459 0 kB
systemd-journal 219 0 kB关闭虚拟内存
$ swapoff -a套路篇: 如何快准狠找到系统内存的问题
内存性能指标
系统
已用内存和剩余内存
共享内存:通过 tmpfs 实现的,他的大小就是 tmpfs 使用内存大小。tmpfs 其实也是一种特殊的缓存
最近在工作中遇到一个tmpfs的坑。 rc.canlog会不断的向 /tmp/canlog/下面写文件,而/tmp 挂载的就是tmpfs。可以看到可用内存在不断减少,而通过top,ps等命令,没有明显的看到是tmpfs引起的。df -h才能发现,/tmpfs /tmp竟然占用了100MB内存。
可用内存是新进程可以使用的最大内存,它包括剩余内存和可回收缓存
缓存包括两部分:一部分是磁盘读取文件的页缓存,用来缓存从磁盘读取的数据,可以加快后续的再次访问。另一部分是,slab 分配器中的可回收内存(内核中的内存)
缓冲区是对原始磁盘块的临时存储,用来缓存将要写入磁盘的数据。统一优化磁盘的写入
引用进程
- 虚拟内存,包括了进程代码段、数据段、共享内存、已经申请的堆内存和已经换出的内存。
- 常驻内存是进程实际使用的物理内存。不包括 swap 和 共享内存
- 共享内存,既包括与其他进程共同使用的真实的共享内存,还包括了加载的动态链接库以及程序的代码段等
- swap 内存,是指通过 swap 换出到磁盘的内存。
性能分析工具
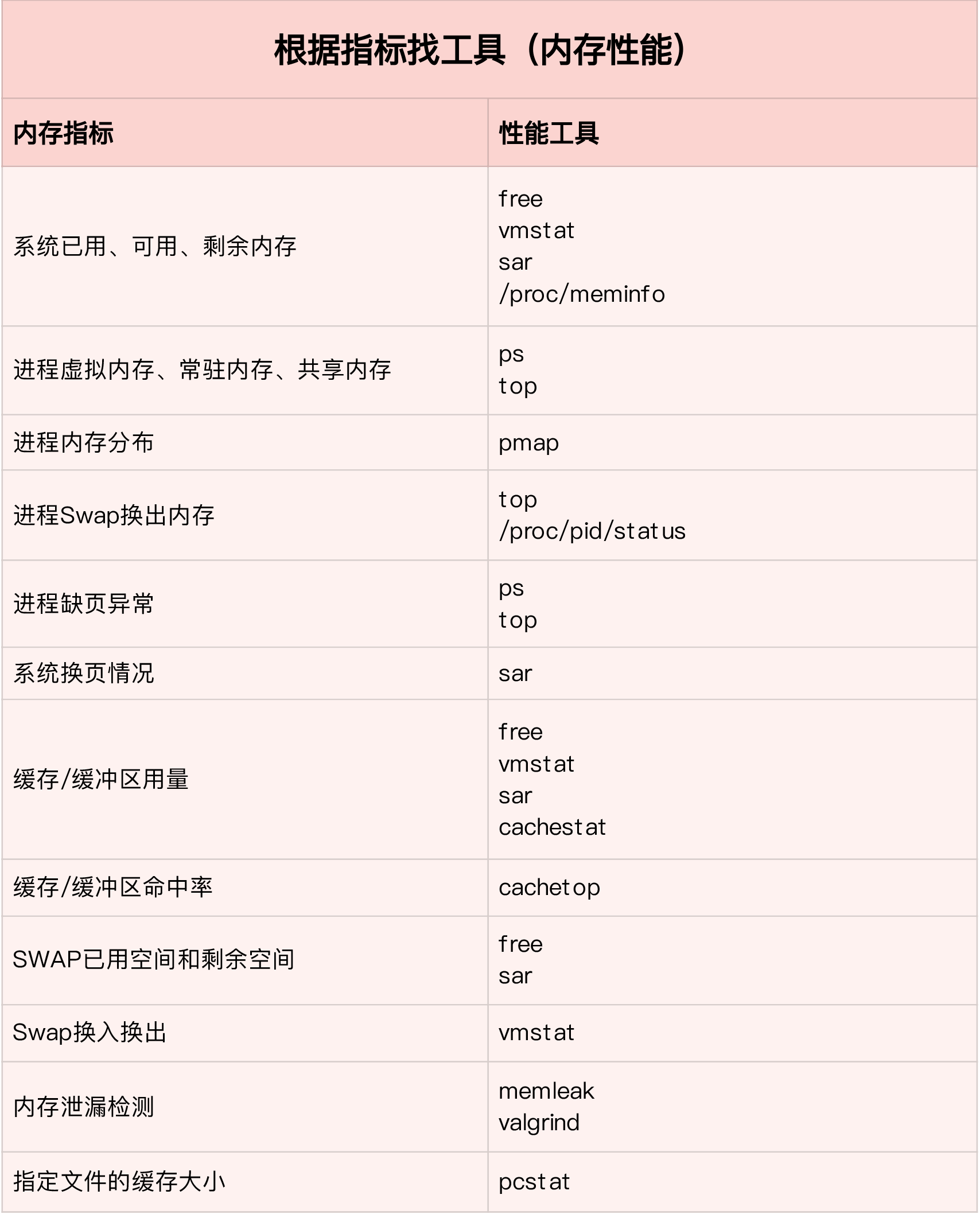
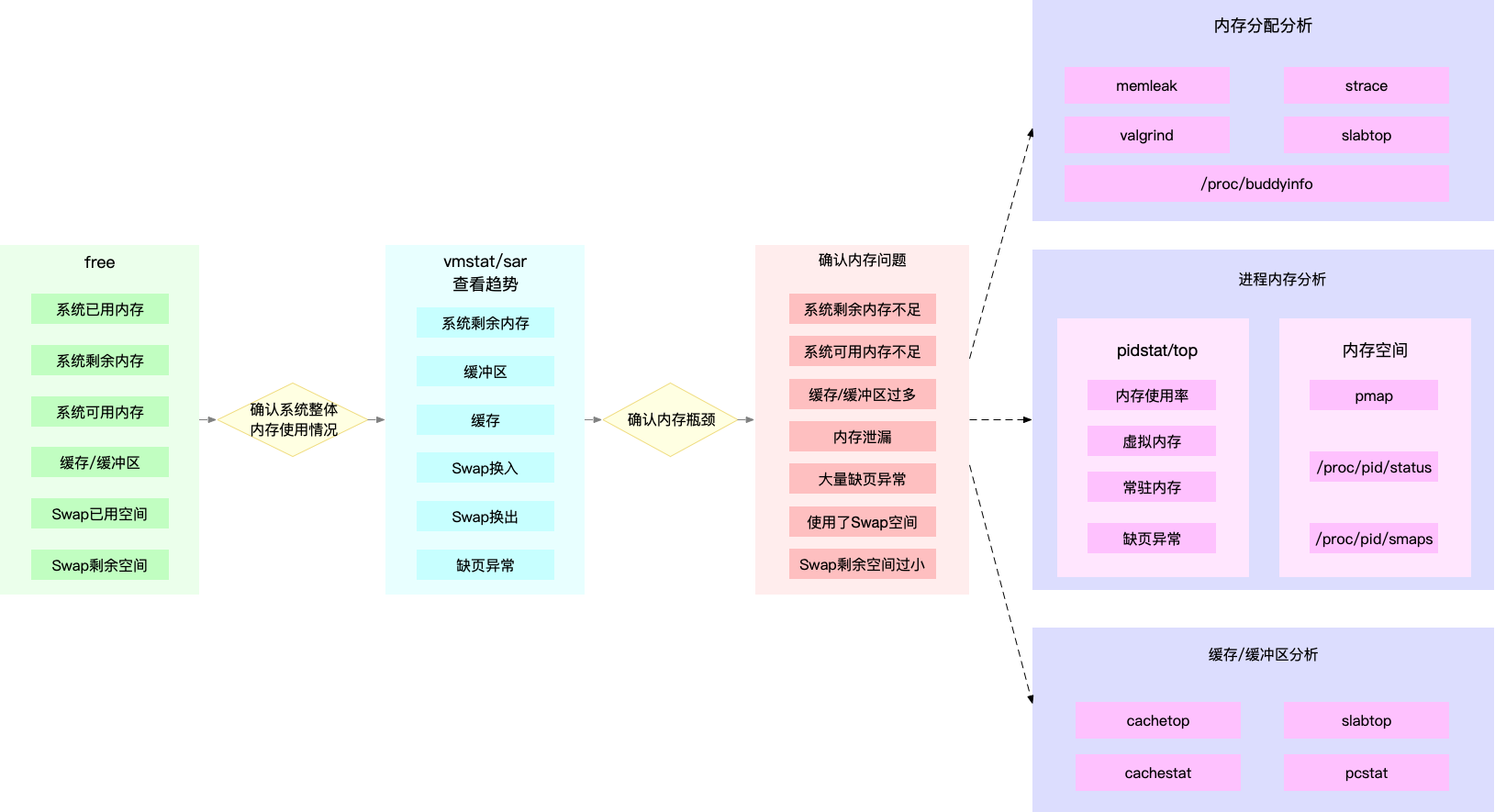
快速定位内存问题
使用 free、top、vmstat、pidstat
分析思路:
- 先用 free 和 top,查看系统整体的内存使用情况
- 在用 vmstat 和 pidstat ,查看一段时间的趋势,从而判断出内存问题的类型
- 最后进行详细分析,比如内存分配分析、缓存/缓冲区分析、具体进程的内存使用分析等
- 针对进程,可以进行 pprof 来查看内存问题,可能是 gc 等导致的